
Today, the editor will share with you the relevant knowledge points about the implementation mechanism of the linux pipeline. , I hope you have gained something after reading this article, let's take a look at it together.
In Linux, a pipe is a communication mechanism that connects the output of one program directly to the input of another program. In essence, a pipe is also a kind of file, but it is different from a general file. The pipe can overcome two problems of using files for communication, specifically: limiting the size of the pipe, and the reading process may work faster than The writing process is fast.
Pipeline is a very important communication method in Linux, which directly connects the output of one program to the input of another program. The pipes that are often said mostly refer to unnamed pipes. Unnamed pipes can only be used between processes with kinship relationships. This is the biggest difference between them and named pipes.
The well-known pipe is called named pipe or FIFO (first in first out), which can be created with the function mkfifo().
The implementation mechanism of Linux pipelines
In Linux, pipelines are a very frequently used communication mechanism. In essence, a pipeline is also a kind of file, but it is different from a general file. A pipeline can overcome two problems of using files for communication, specifically as follows:
Limit the size of the pipeline. In fact, a pipe is a fixed-size buffer. In Linux, the size of this buffer is 1 page, or 4K bytes, so that its size does not grow unchecked like a file. Using a single fixed buffer can also cause problems, such as writing to the pipe may become full, when this happens, subsequent write () calls to the pipe will be blocked by default, waiting for some data to be read, so that Make enough space for the write() call to write.
The reading process may also work faster than the writing process. The pipe becomes empty when all current process data has been read. When this happens, a subsequent read() call will by default block, waiting for some data to be written, which solves the problem of read() calls returning end-of-file.
Note: Reading data from the pipeline is a one-time operation. Once the data is read, it is discarded from the pipeline to free up space for writing more data.
1. The structure of the pipeline
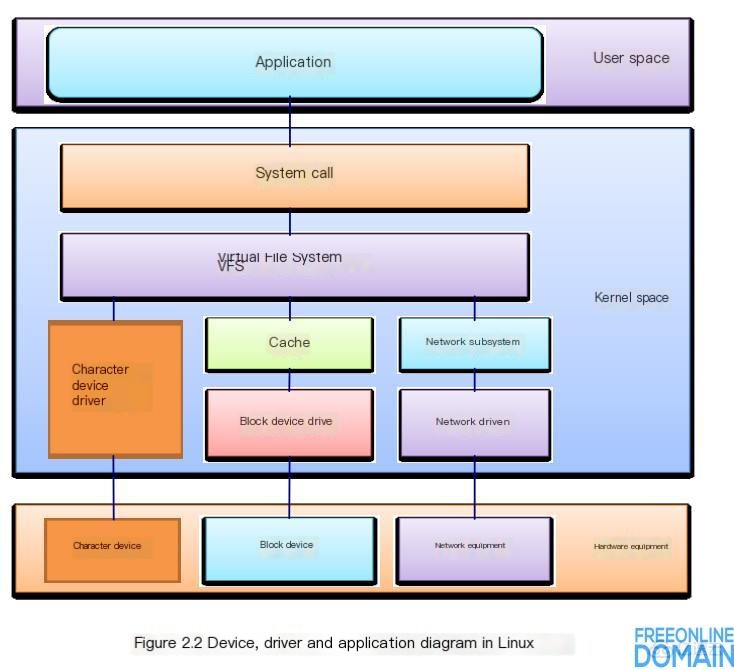
In Linux, the implementation of the pipeline does not use a special data structure, but uses the file structure of the file system and VFS inodesinode. This is achieved by pointing both file structures to the same temporary VFS inode, which in turn points to a physical page.
2. Pipeline reading and writing
The source code of the pipeline implementation is in fs/pipe.c, and there are many functions in pipe.c, among which There are two important functions, namely the pipe read function pipe_read() and the pipe write function pipe_wrtie(). Pipe write functions write data by copying bytes to physical memory pointed to by the VFS inode, while pipe read functions read data by copying bytes in physical memory. Of course, the kernel must use a certain mechanism to synchronize access to the pipeline. For this purpose, the kernel uses locks, waiting queues, and signals.
When the writing process writes to the pipeline, it uses the standard library function write(), and the system can find the file structure of the file according to the file descriptor passed by the library function. The address of the function (that is, the write function) used to perform the write operation is specified in the file structure, so the kernel calls this function to complete the write operation. Before the write function writes data into the memory, it must first check the information in the VFS index node, and the actual memory copy can only be performed when the following conditions are met:
Memory There is enough space in the memory to hold all the data to be written;
The memory is not locked by the reader.
If the above conditions are met at the same time, the write function first locks the memory, and then copies the data from the address space of the writing process to the memory. Otherwise, the writing process sleeps in the waiting queue of the VFS inode, and then the kernel calls the scheduler, which then selects another process to run. The writing process is actually in an interruptible waiting state. When there is enough space in the memory to accommodate the written data, or the memory is unlocked, the reading process will wake up the writing process. At this time, the writing process will receive a signal. After the data is written into the memory, the memory is unlocked, and all reading processes sleeping on the index node will be woken up.
The reading process of the pipeline is similar to the writing process. However, instead of blocking the process, a process can return an error message immediately when there is no data or memory is locked, depending on the file or pipe opening mode. Conversely, the process can sleep in the waiting queue of the index node and wait for the writing process to write data. When all processes have completed their pipeline operations, the pipeline's inodes are discarded and the shared data pages are freed.
Because the implementation of the pipeline involves many file operations, when the reader reads the code in pipe.c after learning about the file system, you will find it not difficult to understand.
Linux pipes are simpler to create and use, the only reason being that they require fewer parameters. RealityNow the same pipe creation target as Windows, Linux and UNIX use the following code snippet:
Create a Linux named pipe
int fd1[2];
if(pipe(fd1))
{
printf("pipe() FAILED: errno=%d",errno);
return 1;
}
Linux pipes have a limit on the size of a write operation before blocking. The kernel-level buffers dedicated to each pipe are exactly 4096 bytes. A write operation larger than 4K will block unless the reader empties the pipe. Actually this is not a restriction, because the read and write operations are implemented in different threads.
Linux also supports named pipes. An early commenter on these numbers suggested that I, to be fair, should compare Linux's Named Pipes to Windows' Named Pipes. I wrote another program that uses named pipes on Linux. I found that for named and unnamed pipes on Linux, the result is no difference.
Linux pipes are much faster than Windows 2000 named pipes, and Windows 2000 named pipes are much faster than Windows XP named pipes.
Example:
#include
Copyright Description:No reproduction without permission。

Knowledge sharing community for developers。
Let more developers benefit from it。
Help developers share knowledge through the Internet。
Follow us







 Español
Español Português
Português